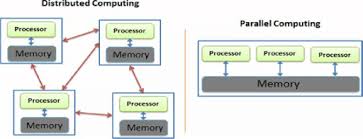
“4.3: Parallel and Distributed Computing” Everything You Need to Know
Related
N
NUM8ERS
0
0
“4.3: Parallel and Distributed Computing” Everything You Need to Know
February 24, 2025
Save
N
NUM8ERS
0
0
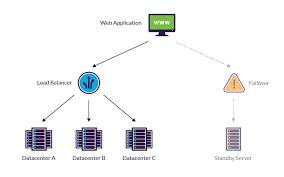
“4.2: Fault Tolerance” Everything You Need to Know
February 24, 2025
Save
N
NUM8ERS
0
0
“4.1: The Internet” Everything You Need to Know
February 24, 2025
Save

N
NUM8ERS
0
0
“Unit 4 Overview: Computer Systems and Networks” Everything You Need to Know
February 24, 2025
Save
More By Author

N
NUM8ERS
0
0
Williams Syndrome - Everything you need to know
March 11, 2025
Save
N
NUM8ERS
0
0
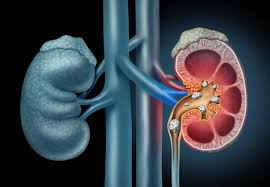
Kidney Stones Causes - Everything you need to know
March 11, 2025
Save

N
NUM8ERS
0
0
Progressive Supranuclear Palsy (PSP) - Everything you need to know
March 11, 2025
Save
N
NUM8ERS
0
0
Pheochromocytoma - Everything you need to know
March 11, 2025
Save