“Fault Tolerance” Everything You Need to Know
Imagine a world where a single hardware failure or software glitch could bring entire systems to a halt—this would mean chaos for everything from financial markets to emergency services. Yet, thanks to fault tolerance, our systems continue running smoothly even when errors occur. Fault tolerance is a critical concept in computer science and engineering that ensures systems remain operational, reliable, and resilient in the face of failures. In this comprehensive guide, we’ll explore everything you need to know about Fault Tolerance—its definition, historical evolution, key components, real-world applications, benefits, common misconceptions, and modern trends. Whether you’re an IT professional, a software developer, or simply curious about how our digital world stays robust, this article will provide you with the insights necessary to appreciate and implement fault-tolerant systems.
Introduction: The Backbone of Reliable Systems
Have you ever wondered how your favorite online services remain up and running during power outages, hardware failures, or unexpected software bugs? The answer lies in fault tolerance—the design of systems that continue to operate, even when parts of them fail. Research shows that companies with fault-tolerant systems experience significantly fewer service interruptions and higher customer satisfaction. In today’s increasingly digital and interconnected world, fault tolerance isn’t just a technical requirement—it’s a cornerstone of modern infrastructure.
In this post, we will cover:
- A clear, concise definition of Fault Tolerance.
- The historical evolution and milestones that shaped fault tolerance.
- An in-depth exploration of its key components, techniques, and types.
- Real-world examples and case studies that illustrate its practical applications.
- The significance and benefits of fault tolerance across industries and everyday life.
- Common misconceptions and FAQs to clarify the concept.
- Modern trends and future directions in fault-tolerant system design.
Let’s dive into the fascinating world of fault tolerance and discover how it keeps our critical systems running smoothly, even in the face of adversity.
What Is Fault Tolerance? A Clear and Concise Definition
Fault Tolerance is the ability of a system to continue functioning properly in the event of the failure of some of its components. This capability is achieved through a combination of hardware and software strategies that detect, isolate, and recover from errors without causing system-wide disruption.
Essential Characteristics
Redundancy:
Fault-tolerant systems often include redundant components (e.g., backup servers, duplicate circuits) so that if one fails, another can take over without interruption.Error Detection and Correction:
Mechanisms such as checksums, parity bits, and error-correcting codes are used to identify and correct errors before they propagate through the system.Graceful Degradation:
Rather than collapsing entirely, a fault-tolerant system continues to operate at a reduced level of performance, ensuring that critical functions remain available.Resilience:
The system’s overall design emphasizes recovery and continuation of service despite faults, whether they are hardware malfunctions, software bugs, or network issues.Availability:
High availability is a primary goal, ensuring that the system is accessible and operational even during partial failures.
These characteristics form the backbone of fault tolerance and are essential for designing systems that can handle real-world challenges without significant disruption.
Historical and Contextual Background
Early Beginnings and the Need for Reliability
Initial Computer Failures:
In the early days of computing, systems were large, complex, and prone to failures. Mainframe computers in the 1950s and 1960s often experienced hardware malfunctions that could bring down an entire operation. This prompted early research into making systems more reliable.Aviation and Space Exploration:
Industries like aviation and space exploration were among the first to adopt fault-tolerant designs. The Apollo missions, for example, required computer systems that could handle unexpected errors during critical operations. Early fault-tolerance concepts were developed to ensure the safety and success of these missions.
Evolution of Fault Tolerance in Computing
Redundancy in Early Systems:
Early fault-tolerant designs often relied on hardware redundancy. Critical systems were built with multiple backup components to ensure continuous operation, a concept that laid the foundation for modern fault tolerance.Advancements in Software Reliability:
As computing systems grew more complex, researchers began to focus not only on hardware redundancy but also on software solutions. Techniques for error detection, fault isolation, and recovery became integral to system design.The Rise of Distributed Systems:
The evolution of networks and distributed computing in the late 20th century introduced new challenges and opportunities for fault tolerance. Systems like the ARPANET and later the Internet required robust designs to handle failures across interconnected networks.
Notable Milestones
NASA’s Fault-Tolerant Systems:
NASA has been a pioneer in developing fault-tolerant systems. From the Apollo missions to the Mars rovers, robust fault-tolerant design has been critical in ensuring mission success in harsh and unpredictable environments.High-Availability Clusters:
In the 1990s, the concept of high-availability (HA) clusters emerged in the IT industry, where groups of computers work together to provide continuous service even if one or more nodes fail. This approach has become standard in modern enterprise systems.Advances in Distributed Computing:
Recent developments in cloud computing and distributed systems have pushed fault tolerance to new heights, enabling services like Google Cloud and Amazon Web Services (AWS) to offer near-constant availability and resilience.
These historical milestones underscore the continuous evolution of fault tolerance from early, rudimentary methods to sophisticated, multi-layered strategies that keep today’s systems robust and reliable.
In-Depth Exploration: Key Components and Techniques in Fault Tolerance
Developing fault-tolerant systems requires a blend of hardware and software strategies designed to detect, isolate, and recover from errors. This section explores the core components and techniques that underpin fault tolerance.
1. Redundancy Strategies
Hardware Redundancy
Definition:
Incorporating multiple instances of critical components (e.g., power supplies, servers, network links) so that if one fails, another can take over.Types:
- Active Redundancy: All components operate simultaneously, and if one fails, the system continues without interruption.
- Passive Redundancy: Backup components remain idle until needed, then activate when a failure occurs.
Example:
Data centers often use redundant power supplies and cooling systems to prevent downtime.
Software Redundancy
Definition:
Implementing duplicate software processes or algorithms to cross-check outputs and ensure correct operation.Techniques:
- Checkpointing: Regularly saving the system state so that it can be restored after a failure.
- Replication: Running multiple instances of a service or process to verify consistency.
Example:
Critical applications may use redundant software processes to ensure that if one process crashes, another can seamlessly continue the operation.
2. Error Detection and Correction Mechanisms
Error Detection
Techniques:
Using techniques such as checksums, parity bits, and cyclic redundancy checks (CRC) to identify errors in data transmission or processing.Application:
Networks and storage systems rely on error detection to maintain data integrity.
Error Correction
Concept:
Once an error is detected, error-correcting codes (ECC) can be used to correct the error automatically.Examples:
- Hamming Codes: Used in memory systems to detect and correct single-bit errors.
- Reed-Solomon Codes: Widely used in digital communications and data storage to correct burst errors.
3. Fault Isolation and Recovery
Fault Isolation
Definition:
The process of identifying and isolating the component or process that has failed, preventing the error from affecting the entire system.Methods:
- Modular Design: Breaking the system into independent modules to contain faults.
- Monitoring and Logging: Continuously monitoring system performance and maintaining logs to trace errors back to their source.
Recovery Mechanisms
Automated Recovery:
Implementing systems that can automatically switch to backup components or restart failed processes.Manual Recovery:
Procedures that allow system administrators to intervene and restore functionality after a fault is detected.Example:
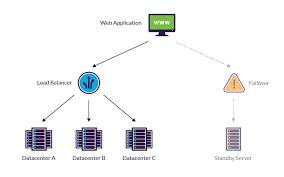
In high-availability clusters, if one server fails, load balancers automatically redirect traffic to functioning servers, ensuring minimal disruption.
4. Fault-Tolerant Architecture Models
High-Availability (HA) Systems
Definition:
HA systems are designed to ensure continuous operation, typically achieving uptimes of 99.999% (five nines). These systems use redundancy and failover mechanisms to minimize downtime.Application:
Critical applications in finance, healthcare, and e-commerce rely on HA systems to guarantee service continuity.
Distributed Systems
Definition:
In distributed systems, computing tasks are spread across multiple nodes, reducing the risk of a single point of failure.Example:
Cloud computing platforms distribute workloads across numerous servers to ensure that if one server fails, the system continues to function seamlessly.
Self-Healing Systems
Concept:
These systems are designed to detect anomalies and automatically recover from failures without human intervention.Techniques:
- Automated Restart: Automatically restarting failed services.
- Dynamic Reconfiguration: Adjusting system configurations on the fly to bypass faulty components.
Example:
Modern microservices architectures often include self-healing capabilities that maintain service continuity even in the face of multiple component failures.
Real-World Examples and Case Studies
Case Study: Data Centers and Cloud Infrastructure
Scenario:
Major cloud providers like Amazon Web Services (AWS) and Google Cloud must ensure that their services remain operational 24/7, despite hardware failures, power outages, or network issues.Implementation:
These providers implement multi-level redundancy, automated failover, and distributed computing across geographically dispersed data centers. Regular backups, real-time monitoring, and dynamic load balancing contribute to their fault-tolerant design.Outcome:
Customers experience near-continuous service availability, even during major outages, highlighting the critical importance of fault tolerance in cloud computing.
Case Study: Aviation Systems
Scenario:
Aircraft systems require fault tolerance to ensure safety during flight. Critical systems, such as navigation and engine controls, must continue to operate reliably despite potential hardware failures.Implementation:
Redundant hardware components, rigorous error-checking algorithms, and real-time fault isolation techniques are used to ensure that any failure does not compromise flight safety.Outcome:
The fault-tolerant design of aviation systems has contributed to an exceptional safety record in modern air travel, demonstrating the life-saving potential of these technologies.
Case Study: Financial Trading Platforms
Scenario:
Financial trading platforms operate in environments where milliseconds matter. A single failure in these systems can result in significant financial loss.Implementation:
These platforms use high-availability clusters, redundant network paths, and real-time monitoring to detect and recover from faults instantly. Automated algorithms ensure that trading continues uninterrupted even if a component fails.Outcome:
The robust fault-tolerant design of trading platforms helps maintain market stability and investor confidence, while also reducing operational risks.
Case Study: Healthcare Information Systems
Scenario:
In hospitals, patient data must be accessible at all times, especially in emergency situations.Implementation:
Healthcare information systems employ fault tolerance through redundant servers, backup power supplies, and secure data replication. These systems ensure that electronic health records (EHRs) and diagnostic information are always available to medical professionals.Outcome:
Improved patient care, faster response times, and enhanced system reliability are achieved, underscoring the critical importance of fault tolerance in healthcare.
The Importance, Applications, and Benefits of Fault Tolerance
Understanding and implementing Fault Tolerance is vital across numerous domains. Here’s why fault tolerance is so important:
Enhancing System Reliability and Uptime
Minimizing Downtime:
Fault-tolerant systems are designed to continue operating even when some components fail, ensuring high availability and minimizing costly downtime.Resilience:
By isolating faults and automatically recovering from errors, fault tolerance enhances the overall resilience of systems, making them more robust in the face of unexpected issues.
Protecting Data and Ensuring Security
Data Integrity:
Error detection and correction mechanisms protect data from corruption, ensuring that information remains accurate and reliable.Secure Operations:
Redundant and self-healing systems help maintain the security of critical operations, which is particularly important in sensitive industries such as finance and healthcare.
Driving Efficiency and Innovation
Optimized Resource Usage:
By minimizing interruptions and errors, fault-tolerant systems optimize resource usage, leading to more efficient operations.Encouraging Innovation:
Reliable, fault-tolerant systems enable organizations to experiment with new technologies and processes without fear of catastrophic failure, fostering a culture of innovation.
Broad Applications Across Industries
Business and Finance:
Fault tolerance ensures that business-critical applications and financial systems remain operational, protecting revenue and customer trust.Public Services and Infrastructure:
Government and public safety systems rely on fault tolerance to deliver uninterrupted services, from emergency response to utility management.Research and Development:
Scientific experiments and complex simulations depend on fault-tolerant systems to produce accurate and reliable results.
Addressing Common Misconceptions and FAQs
Despite its importance, several misconceptions about Fault Tolerance persist. Let’s clarify some common myths and address frequently asked questions.
Common Misconceptions
Misconception 1: “Fault tolerance is only necessary for mission-critical systems.”
Reality: While fault tolerance is essential in critical applications (like aviation and healthcare), its principles improve reliability and user experience in everyday systems, from web services to mobile applications.Misconception 2: “Building a fault-tolerant system is prohibitively expensive and complex.”
Reality: Although achieving fault tolerance can require additional investment, the long-term benefits in reduced downtime, enhanced reliability, and improved efficiency often outweigh the initial costs.Misconception 3: “Fault-tolerant systems are infallible.”
Reality: No system is completely immune to failures. Fault tolerance minimizes the impact of failures and allows for rapid recovery, but it does not guarantee perfection in every scenario.
Frequently Asked Questions (FAQs)
Q1: What is fault tolerance in simple terms?
A1: Fault tolerance is the ability of a system to continue operating correctly even if one or more of its components fail.
Q2: Why is fault tolerance important for businesses?
A2: Fault-tolerant systems reduce downtime, protect data, and ensure that critical operations continue without interruption, which is vital for maintaining productivity and customer trust.
Q3: What are some common methods to achieve fault tolerance?
A3: Common methods include hardware and software redundancy, error detection and correction mechanisms, and the design of self-healing systems that can automatically recover from failures.
Q4: Can fault tolerance be applied to personal computing?
A4: Yes. While it is more commonly associated with large-scale systems, many personal devices and applications incorporate fault-tolerant features to improve reliability and performance.
Modern Relevance and Current Trends in Fault Tolerance
The concept of Fault Tolerance continues to evolve as technology advances. Here are some modern trends and emerging practices shaping its future:
Cloud Computing and Distributed Systems
Scalable Resilience:
Cloud platforms like AWS, Google Cloud, and Microsoft Azure have built-in fault tolerance through distributed architectures, ensuring that services remain available even if individual components fail.Microservices Architecture:
Modern software architectures use microservices, which are inherently fault-tolerant due to their distributed nature. If one service fails, others continue to operate independently.
Advancements in Hardware and Software
Redundancy in Data Centers:
Data centers are now designed with multiple layers of redundancy—including power, cooling, and networking—to minimize downtime and ensure continuous service.Self-Healing Systems:
The integration of artificial intelligence and machine learning enables systems to automatically detect, isolate, and recover from faults without human intervention.
Network Security and Reliability
Enhanced Security Protocols:
Advanced encryption, multi-factor authentication, and zero-trust architectures are integral to fault-tolerant systems, ensuring that even when components fail, security is not compromised.Disaster Recovery Planning:
Organizations are increasingly focusing on comprehensive disaster recovery plans that incorporate fault-tolerant design principles, ensuring rapid recovery from natural disasters or cyber-attacks.
Internet of Things (IoT) and Edge Computing
Real-Time Fault Tolerance:
With the proliferation of IoT devices, fault tolerance at the edge of the network is critical. These devices need to operate reliably even in harsh or unpredictable environments.Decentralized Networks:
Fault-tolerant principles are being applied in decentralized networks, including blockchain and distributed ledger technologies, to enhance security and reliability.
Conclusion: The Enduring Value of Fault Tolerance
Fault Tolerance is not just a technical luxury—it’s a necessity in today’s interconnected, high-stakes digital world. From ensuring that critical systems like healthcare and finance remain operational to enhancing the reliability of everyday applications, fault tolerance underpins the performance and resilience of our most essential technologies.
Key Takeaways
Crucial for Reliability:
Fault tolerance ensures that systems continue to function despite failures, reducing downtime and safeguarding data.Wide-Ranging Benefits:
Its principles improve efficiency, enhance security, and support scalability, benefiting industries from cloud computing to critical infrastructure.Modern Innovation:
Advances in cloud computing, AI, and distributed systems are driving new developments in fault-tolerant design, ensuring that our systems can handle increasingly complex challenges.Empowering Continuous Improvement:
By understanding and implementing fault-tolerant strategies, organizations can create resilient systems that not only survive failures but also adapt and thrive in a dynamic environment.
Call-to-Action
Reflect on your own systems and applications—how robust are they in the face of unexpected failures? Whether you’re an IT professional, a software developer, or someone interested in enhancing system reliability, exploring fault tolerance is key to building resilient, high-performing systems. We invite you to share your experiences, ask questions, and join the conversation about the transformative power of fault tolerance. If you found this guide helpful, please share it with colleagues, friends, and anyone looking to improve their system reliability and operational efficiency.
For more insights into technology, digital transformation, and advanced computing, check out reputable sources such as Harvard Business Review and Forbes. Embrace fault tolerance and build a future of resilient, reliable, and innovative systems!
Additional Resources and Further Reading
For those who wish to dive deeper into Fault Tolerance, here are some valuable resources:
Books:
- “Designing Data-Intensive Applications” by Martin Kleppmann
- “Fault-Tolerant Systems” by Israel Koren and C. Mani Krishna
- “Reliable Distributed Systems: Technologies, Web Services, and Applications” by Kenneth P. Birman
Online Courses and Workshops:
Websites and Articles:
Communities and Forums:
- Engage with IT professionals on Reddit’s r/sysadmin and r/networking for practical advice and case studies.
- Join LinkedIn groups dedicated to cloud computing, distributed systems, and fault-tolerant design for expert insights.
Final Thoughts
Fault tolerance is the unsung hero of reliable computing. It ensures that our systems remain robust in the face of failure, enabling critical services to continue operating even under adverse conditions. By understanding and implementing fault-tolerant strategies, we not only safeguard our technology but also drive continuous improvement and innovation. Whether you’re building the next generation of cloud services, designing secure networks, or simply ensuring that your applications run smoothly, fault tolerance is the key to resilient and efficient systems.
Thank you for reading this comprehensive guide on Fault Tolerance. We welcome your feedback, questions, and success stories—please leave your comments below, share this post with your network, and join our ongoing conversation about building resilient systems for a rapidly evolving digital world.
Happy coding, and here’s to a future of systems that are as robust as they are innovative!





